在分析一段音訊時,我們通常將音訊切成比較短的單位,稱為音框(frame),通常一個音框必須包含數個基本週期(fundamental period),才能充分擷取音訊的特徵。接著我們就可以從一個音框內提取聲學特徵(acoustic features),以便進行進一步的分析。通常我們允許音框和音框之間可以重疊,而每秒出現的音框數則稱為音框率(frame rate),音框率越高,則所需要的計算資源越大。以下是從一段音訊切出多個音框的示意圖:
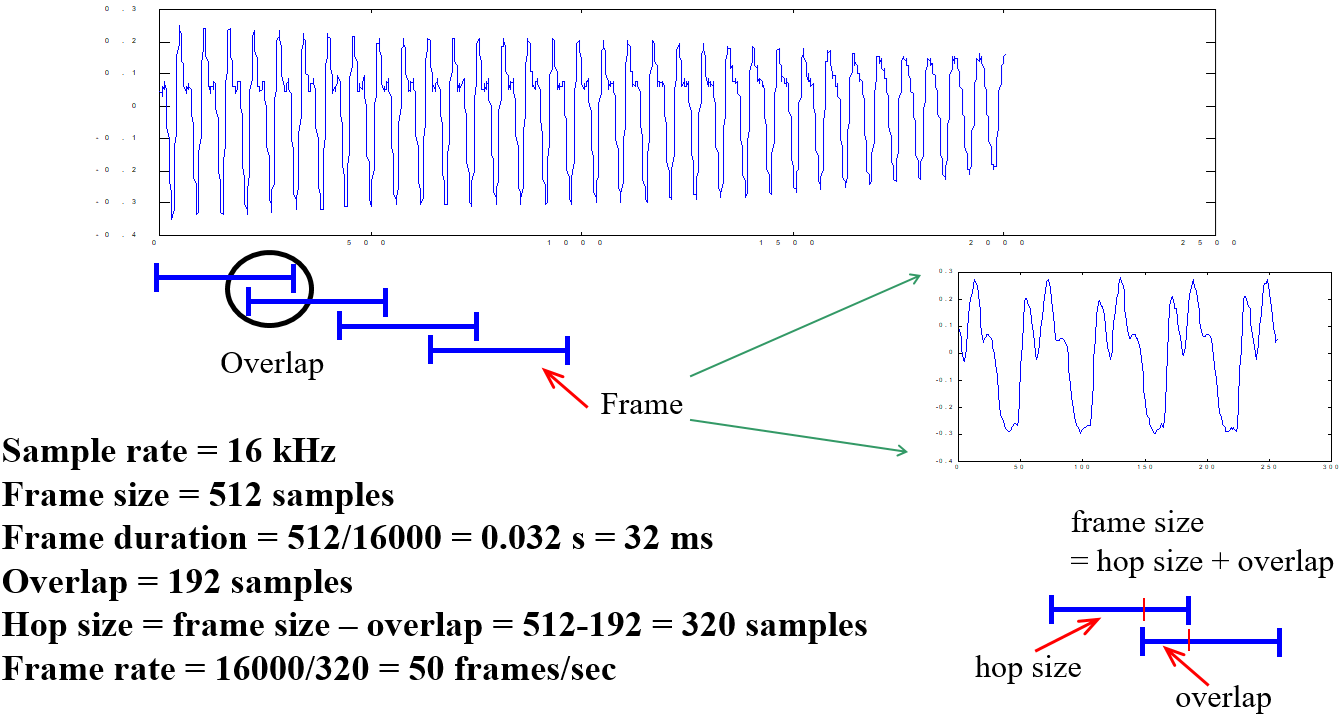
圖 5.:由一段音訊中切出音框。 |
我們人耳聽到一段音訊後,立即可以感受的的特性有音量(volume)、音高(pitch)和音色(timbre),但我們要使用電腦來分析音訊,就必須使用數學公式來描述上列特性,以「逼近」人耳的感覺。這些由每一個音框所抽出來的數值或向量就稱為聲學特徵(acoustic features),說明如下。
- 音量:代表音訊的強度(intensity)或能量(energy),通常可以使用音訊的震幅來類比,震幅越大,音量越大,音量的單位是分貝(decibel)。
- 音高:代表音訊的高低,例如女生的歌聲會比較高,而男生的歌聲會比較低。通常我們使用在每一秒內出現的基本週期的個數,來代表音高。舉例來說,我們可以先用肉眼觀察音叉的波形,抓出基本週期的位置,然後決定音高,方法如下圖示:
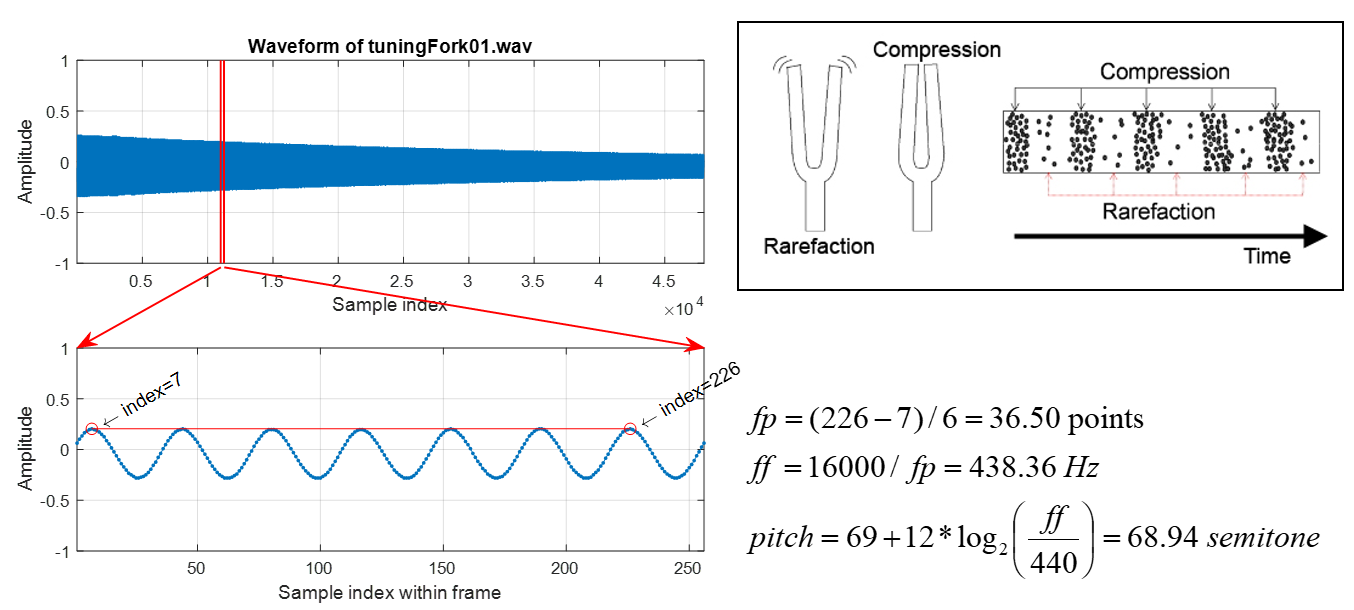
圖 5.:由觀察法得到音叉聲音的一個音框的音高。 |
在上圖中,我們所處理的聲音內容是音叉的錄音,取樣頻率是 16 KHz(也就是每秒的聲音取樣點是 16000)。我們先切出一個音框,長度是 256 點(時間長度是 512/16000 = 0.032 sec = 32 msec),然後使用觀察法,在這個音框內挑到 6 個完整的基本週期,開始於第 7 點,結束於第 226 點,因此基本週期的時間長度是 (226-7)/6 = 36.5 points,而對應的基本頻率則是 16000/36.5 = 438.36 Hz,代表每秒鐘大約有將近 438 個基本週期。
利用類似的方式,我們也可以決定一個人講話的音高,如下:
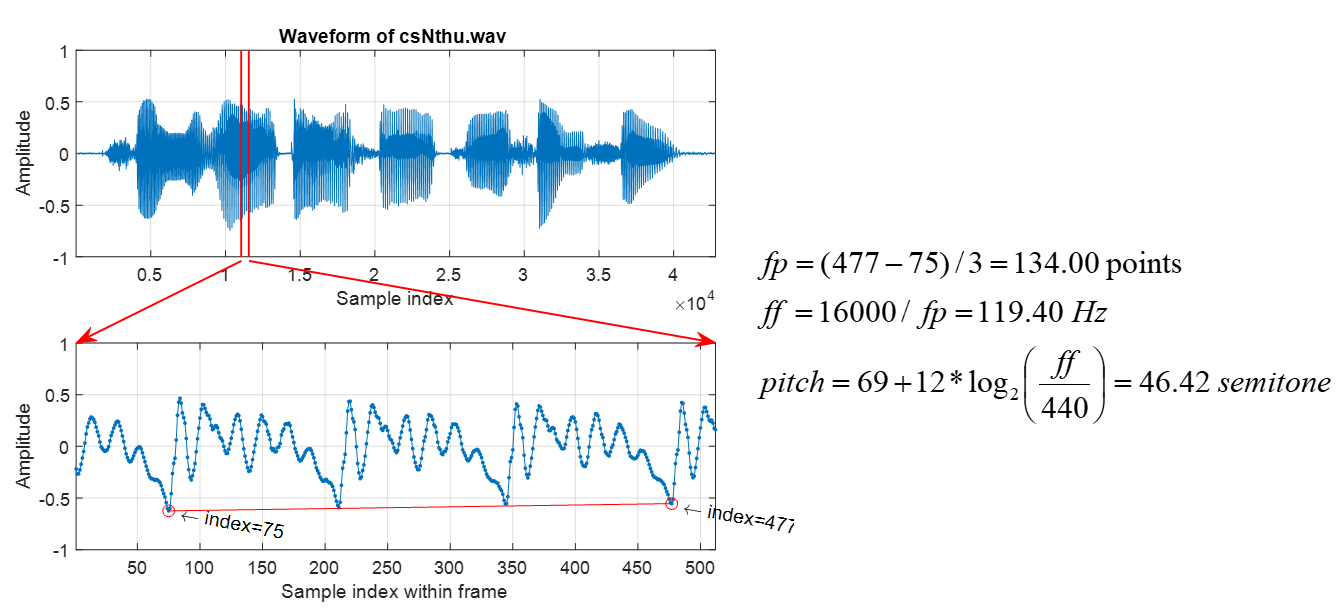
圖 5.:由觀察法得到一句語音的一個音框的音高。 |
在上圖中,我們所處理的聲音內容是「清華大學資訊系」,取樣頻率是 16 KHz(也就是每秒的聲音取樣點是 16000)。我們先切出一個音框,長度是 512 點(時間長度是 512/16000 = 0.032 sec = 32 msec),然後使用觀察法,在這個音框內挑到 3 個完整的基本週期,開始於第 75 點,結束於第 477 點,因此基本週期的時間長度是 (477-75)/3 = 134 points,而對應的基本頻率則是 16000/134 = 119.40 Hz,代表每秒鐘大約有將近 119 個基本週期。
由於我們人耳對於聲音高低的感覺,並不是直接和聲音的基本頻率成正比,而是和聲音的基本頻律的對數值成正比,因此我們可以使用半音差(semitone)來表示音高,公式如下:
$$
pitch = 69 + 12 \log_2 \left(\frac{freq}{440} \right)
$$
其中 $freq$ 是以 Hz 為單位的基本頻率值,而 $pitch$ 則是以 semitone 為單位的音高值,這個音高值又稱為 MIDI number,可以直接對應到鋼琴的每一個琴鍵,例如當 $freq=440$ 時,所對應到的音高是 $pitch=69$,這就是鋼琴的中央 La(或稱 middle A、A440、A4)鍵。
- 音色:代表音訊的內容,例如「ㄚ」和「ㄛ」的發音方式不同,就會產生不同的音色,另外不同樂器所產生的聲音,也是屬於不同的音色。通常我們使用音訊在不同頻率的能量分布,來代表音色,因此經由快速傅立葉轉換(fast Fourier transform, FFT)來將一個音框的訊號轉成幅度頻譜(magnitude spectrum),就可以做為音色的特徵。但以幅度頻譜的特徵,常受到音高的影響,而有協波(harmonics)的現象,因此另一個典型的音色特徵是 MFCC (mel-frequency cepstral coefficients) ,比較不會受到協波的影響,可以代表人耳對音色的感受,此特徵常用在語音辨識。
上述的聲學特徵,表現在時域的波形方面,可以顯示如下:
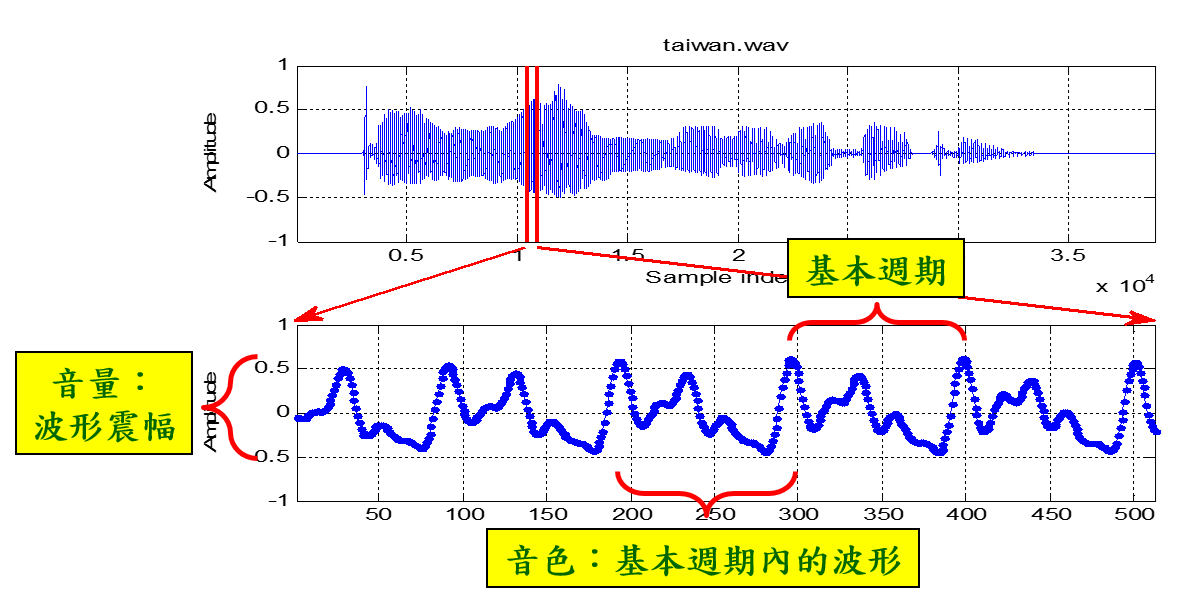
圖 5.:聲學特徵顯示於時域的對應表現。 |
若是使用 FFT將一個音框的訊號轉成幅度頻譜,上述的聲學特徵可以顯示如下:
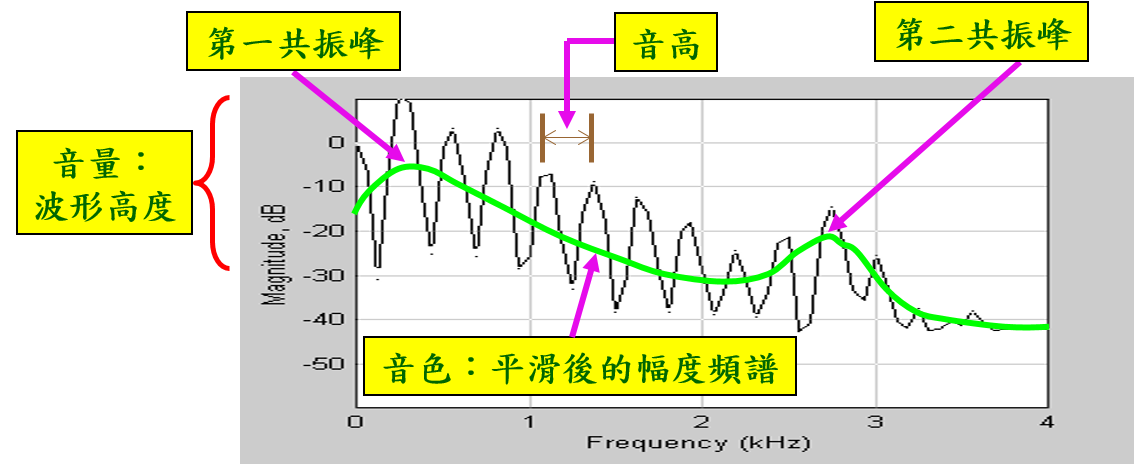
圖 5.:聲學特徵顯示於頻域的對應表現。 |
把一段音訊切成音框的集合後,我們就可以針對每個音框來抽取聲學特徵(可能是一個數值,例如音量或是音高,或是一個向量,例如頻譜或是 MFCC),不同的應用會需要用到不同的聲學特徵,電腦必須能夠自動地計算這些特徵,才能進一步進行後續的分析或分類。以下各小節將說明音訊辨識的各項應用,以及可能用到的聲學特徵及相關的機器學習方法。
作業
- 一段音訊的取樣頻率是 16 kHz,若是音框長度是 320 個取樣點,請回答下列問題:
- 如果音框之間的重疊是 120 點,那麼對應的音框率是?
- 如果音框率是 100 frame/sec,則音框之間的重疊應該是幾點?
- 假設我從我的語音訊號抽出一個音框,如下圖。如果取樣頻率是 8 kHz,請計算這個音框的基本頻率。(在選取基本週期來進行平均時,基本週期的個數必須越多越好,以求穩定。)
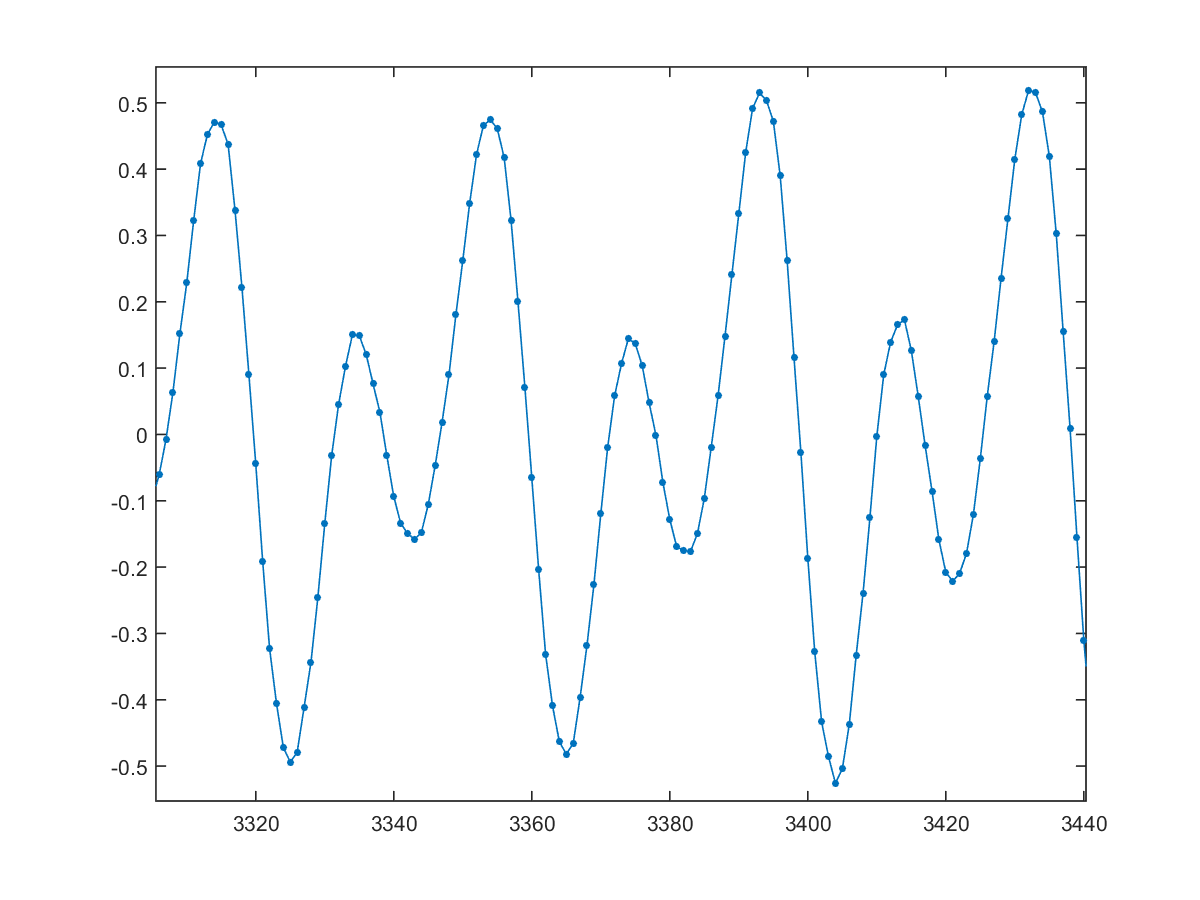
圖 5.:請由此音框計算對應的基本頻率。 |
- 請從網路上尋找資訊,來解釋下列名詞(請盡量使用數學方程式來說明),並說明在日常生活中,何時會遇到這些現象:
- 拍頻(beat frequency)
- 杜普勒效應(Doppler effect)
Audio Signal Processing and Recognition (音訊處理與辨識)
